The Season Opener Problem
The 2026 Australian GP was the first race under F1's most sweeping regulation overhaul in a decade. New aerodynamic philosophy. Narrower tires. A 50/50 ICE-to-electric power split replacing the old hybrid architecture. Active aero where both wings dynamically adjust between corner and straight-line modes — every car, every lap, replacing the old DRS system entirely.
None of this had ever been raced at distance. No team had managed battery depletion over 58 competitive laps. No historical model had training data for these cars.
V1 was built to handle that: not by pretending the uncertainty didn't exist, but by building a system whose architecture explicitly distributes responsibility across three models that each handle it differently.
Qualifying Grid
| Pos | Driver | Team | Gap | |:----|:-------|:-----|:----| | P1 | George Russell | Mercedes | 1:18.518 | | P2 | Kimi Antonelli | Mercedes | +0.3s | | P3 | Isack Hadjar | Red Bull | — | | P4 | Charles Leclerc | Ferrari | — | | P5 | Oscar Piastri | McLaren | — | | P7 | Lewis Hamilton | Ferrari | — | | P20 | Max Verstappen | Red Bull | Crashed in Q1 | | DNS | Carlos Sainz | Williams | ERS failure |
Mercedes locked out the front row with a 0.3s gap to the field. Russell's 1:18.518 was a statement lap — clean, clinical, with the car responding exactly as Mercedes' simulations predicted. The interesting story going in was everyone else: Red Bull visibly off-pace, Ferrari within striking distance but not dominant, and Verstappen needing a miracle from P20.
Ensemble Output
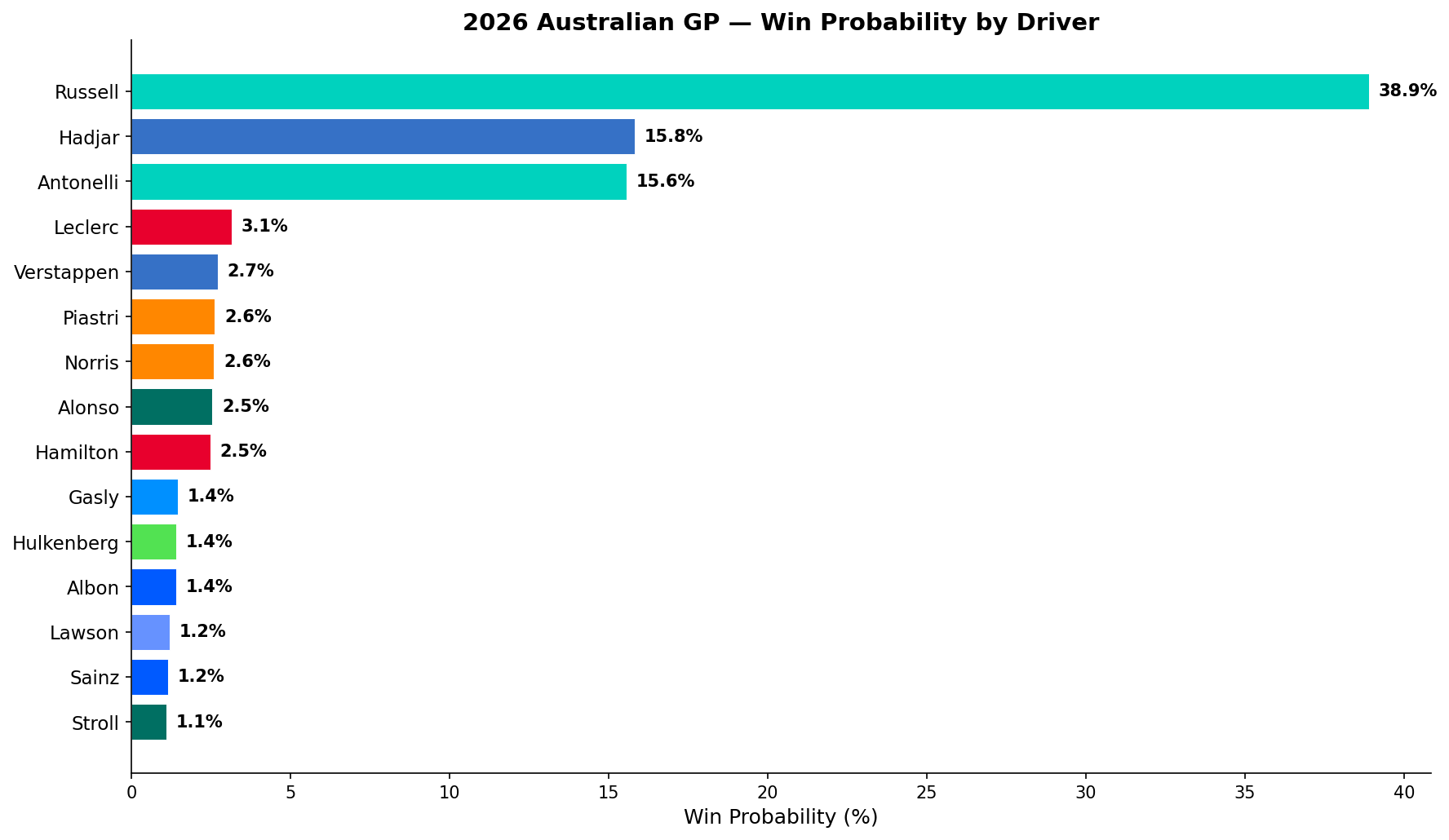
| Driver | XGBoost | Monte Carlo | Bayesian | Final | |:-------|:-------:|:-----------:|:--------:|:---------:| | Russell | 27.4% | 75.8% | 9.3% | 38.9% | | Hadjar | 35.2% | 4.8% | 6.1% | 15.8% | | Antonelli | 18.9% | 22.4% | 6.7% | 15.6% | | Leclerc | — | — | 7.1% | 3.1% | | Verstappen | 2.2% | 0.0% | 6.5% | 2.7% |
Why The Models Disagreed
This is where the ensemble earns its keep. The disagreement between models isn't noise — it's information.
Hadjar: XGBoost's big call. The pattern-matching model gave Hadjar 35.2% — actually higher than Russell's 27.4%. Why? Because XGBoost has 12 years of training data showing that Red Bull drivers starting P3 with strong constructor ratings win a lot of races. It's doing its job correctly: reading the historical signal. But Monte Carlo gives Hadjar only 4.8% because the physics of a 0.4s qualifying gap over 58 laps of limited overtaking at Albert Park is brutal to overcome in simulation. The ensemble's 15.8% is the right answer: respect the historical pattern while discounting it against the physical reality.
Verstappen: The Bayesian problem. Monte Carlo says 0.0% from P20. XGBoost says 2.2%. But the Bayesian model gives him 6.5%. The reason is philosophically important: a four-time world champion's prior win probability should never be zero from any grid position. The Bayesian model is encoding the fact that extraordinary drivers have pulled off extraordinary things before. It's not wrong to assign near-zero probability to a P20 win, but it's also wrong to assign exactly zero to a driver of Verstappen's caliber.
Hamilton at P7 — the quiet one. The Bayesian model gave Hamilton 6.6% despite starting P7. Seven world championships, two regulation-change dominances in 2014 and 2017. The model's prior for "Hamilton in a new-regulation year" is structurally elevated. The Bayesian component was hedging its bets on a driver who has historically thrived when the rulebook gets rewritten.
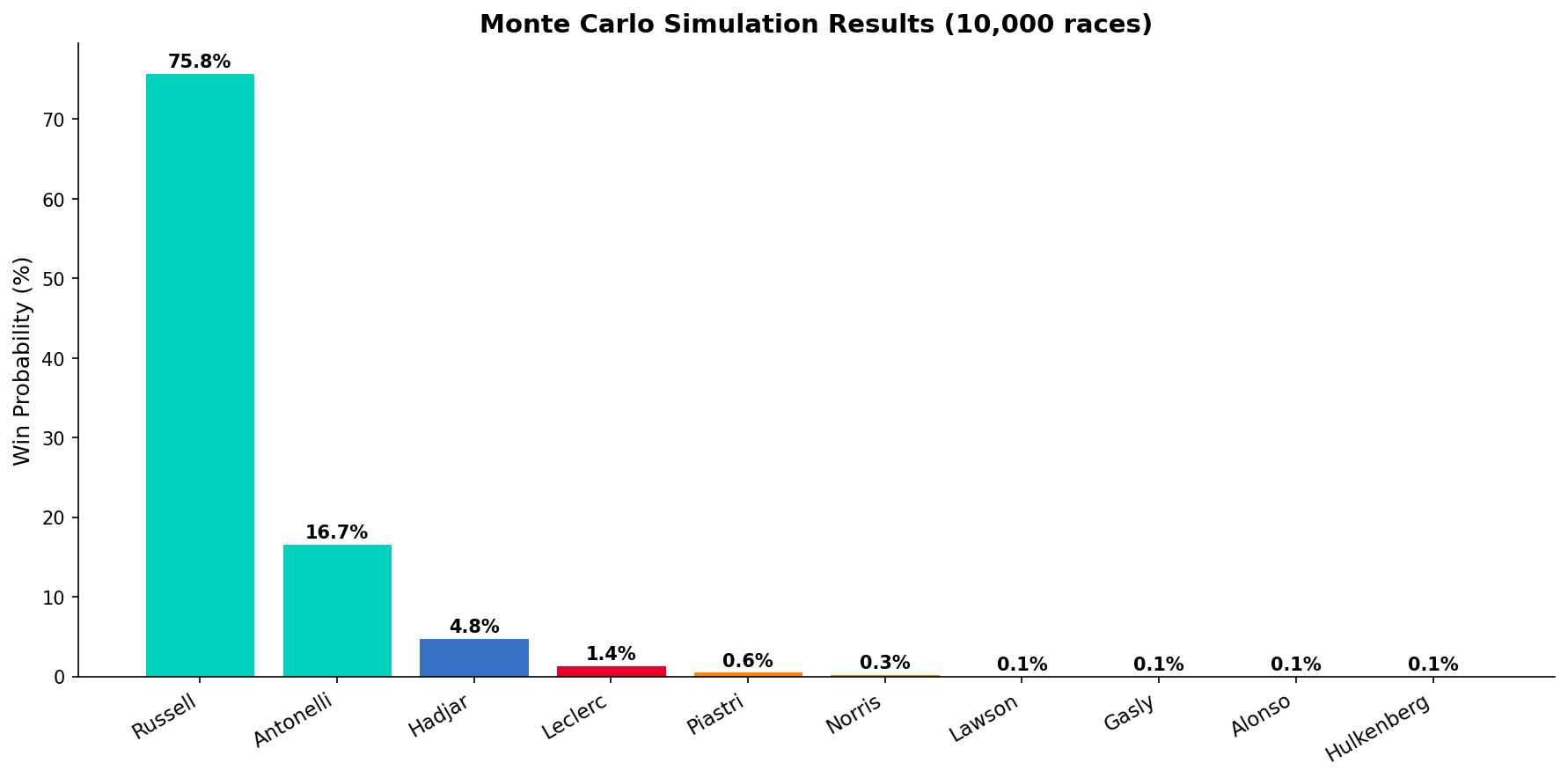
Monte Carlo: What The Physics Said
Running 10,000 simulated races, lap by lap, the simulator's core finding was unambiguous: Russell's qualifying advantage was near-insurmountable at a circuit with limited overtaking opportunities.
For each of the 10,000 simulations:
- Lap times sampled from
Normal(mu_driver, sigma)— mean anchored to qualifying pace, sigma calibrated to practice consistency - Tire degradation applied per lap — the 2026 narrower compounds showed a nonlinear "cliff" after approximately 18 laps on softs
- Safety car rolled at 1% per lap (calibrated to Albert Park's ~60% per-race historical SC rate)
- DNF probability doubled from baseline (year-one regulation reliability risk)
- Fuel correction applied — cars shed 0.03s/lap as they lighten over race distance
The safety car analysis was particularly telling. With a 60% per-race SC probability, a lap 1–15 deployment changes everything — it's the only scenario where Verstappen becomes relevant. But even then, his simulated win probability only climbed from 0.0% to ~0.8%. The deficit from P20 is that structural.
Feature Importance
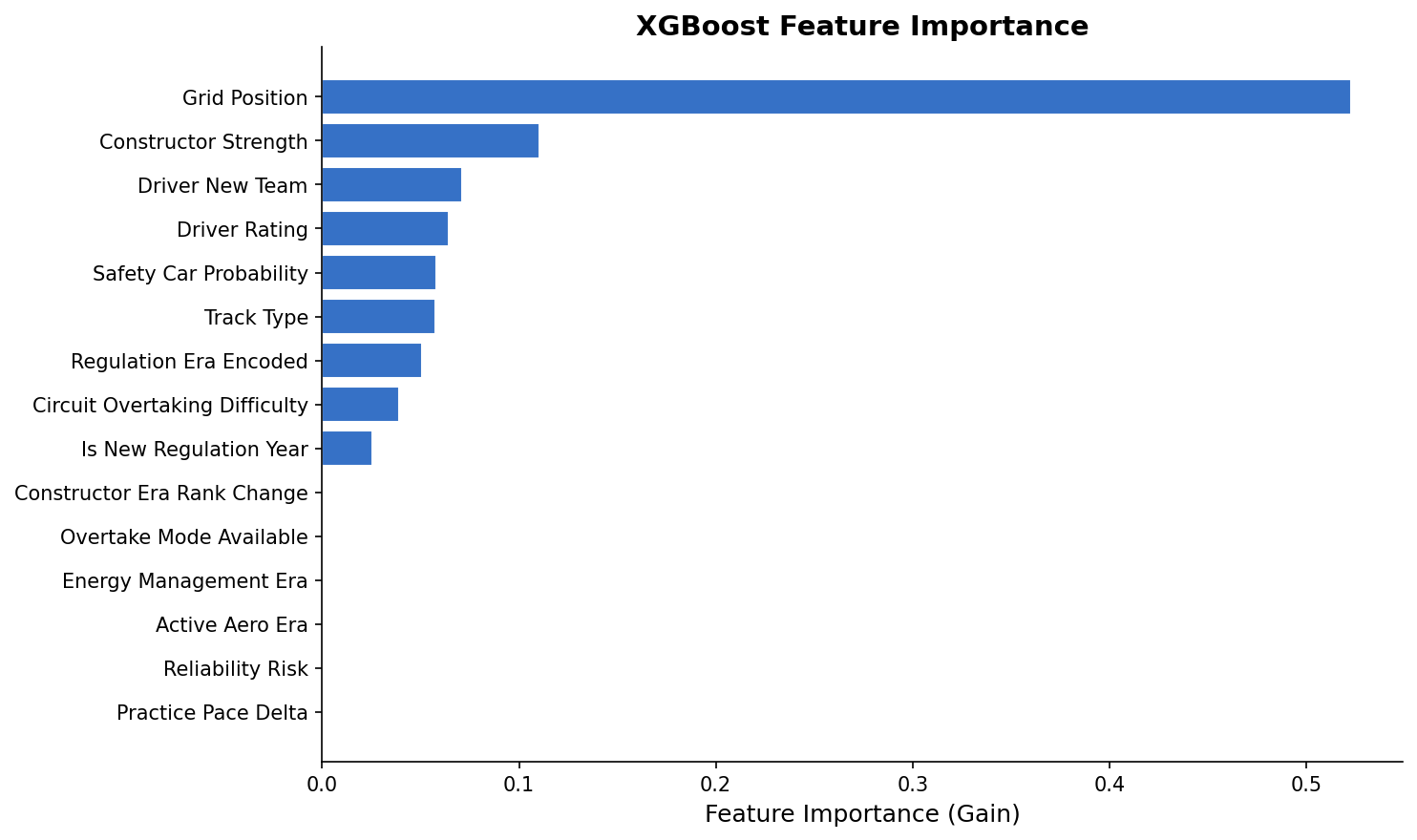
grid_position dominated, as expected. Albert Park has historically low overtaking rates — the pole sitter wins 57% of races there. But constructor_strength was the second-most predictive feature, which is the model correctly encoding that F1 is a constructor's championship first. The 2026-specific flags (active_aero_era, energy_management_era) functioned primarily as uncertainty inflators — widening confidence intervals rather than shifting predictions in either direction.
What V1 Got Wrong
Running the model against actual race results revealed three systematic failures that V2 would address:
1. FP2 long-run pace was missing. Hamilton finished well ahead of his predicted 2.5% win probability. The model underweighted him because FP2 practice data (the best race-pace proxy) wasn't available at the time of prediction. In V2, fp1_pace_delta became a Tier 1 feature.
2. Practice-to-qualifying divergence was invisible. Drivers who significantly outperform in qualifying relative to their practice positions were invisible to V1. fp1_to_quali_divergence — the difference between FP1 position and qualifying position — became a new V2 feature.
3. Reliability risk was underweighted. V1 used a 2× DNF multiplier for year-one regulation teams. The actual DNF rate in the race was higher, validating the case for V2's 3× multiplier.
Technical Reports
Tech Stack
- Python: NumPy, SciPy, Pandas
- ML: XGBoost 2.0, Scikit-learn
- Data: FastF1, Jolpica-F1 API, OpenF1 API
- Visualization: Matplotlib, Seaborn
- Validation: GroupKFold CV (race-ID grouped)